from asyncio.constants import ACCEPT_RETRY_DELAY
from urllib.request import urlopen
webpage = urlopen('http://www.python.org')
#假设要提取刚才所打开网页中链接About的相对URL,可使用正则表达式
import re
text = webpage.read()
m = re.search(b'<a href="([^"]+)" .*?>about</a>',text,re.IGNORECASE)
m.group(1)
'/about/'
#如果要给下载的副本指定文件名,可通过第二个参数来提供。
urlretrieve('http://www.python.org','C:\\python_webpage.html')
#代码清单14-3 基于SocketServer的极简服务器
from socketserver import TCPServer, StreamRequestHandler
class Handler(StreamRequestHandler):
def handle(self):
addr = self.request.getpeername()
print('Got connection from',addr)
self.wfile.write('Thank you for connecting')
server = TCPServer(('',1234),Handler)
server.serve_forever()
#代码清单14-4 分叉服务器
from socketserver import TCPServer,ForkingMixIN,StreamRequestHandler
class Server(ForkingMixIN,TCPServer):pass
class Handler(StreamRequestHandler):
def handle(self):
addr = self.request.getpeername()
print('Got connection from',addr)
self wfile.write('Thank you for connecting')
server = Server(('',1234),Handler)
server.serve_forever()
#代码清单14-5 线程化服务器
from socketserver import TCPServer,ThreadingMixIN,StreamRequestHandler
class Server(ThreadingMixIN,TCPServer):pass
class Handler(StreamRequestHandler):
def handle(self):
addr = self.request.getpeername()
print('Got connection from',addr)
self.wfile.write('Thank you for connecting')
server = Server(('',1234),Handler)
server.serve_forever()
#代码清单14-6 使用select的简单服务器
import socket,select
s = socket.socket()
host = socket.gethostname()
port = 1234
s.bind((host,port))
s.listen(5)
inputs = [s]
while True:
rs, ws, es = select.select(inputs,[],[])
for r in rs:
if r is s:
c,addr = s.accept()
print('Got connection from',addr)
inputs.append(c)
else:
try:
data = r.recv(1024)
disconnected = not data
except socket.error:
disconnected = True
if disconnected:
print(r.getpeername(),'disconnected')
inputs.remove(r)
else:
print(data)
#代码清单14-7 使用poll的简单服务器
import socket,select
s = socket.socket()
host = socket.gethostname()
port = 1234
s.bind((host,port))
fdmap = {s.fileno():s}
s.listen(5)
p = select.poll()
p.register(s)
while True:
events = p.poll()
for fd,event in events:
if fd in fdmap:
c, addr = s.accept()
print('Got connection from',addr)
p.register(c)
fdmap[c.fileno()] = c
elif event & select.POLLIN:
data = fdmap[fd].recv(1024)
if not data:# 没有数据 --连接已关闭
print(fdmap[fd].getpeername(),'disconnected')
p.unregister(fd)
del fadmap[fd]
else:
print(data)
#代码清单14-8 使用Twisted创建的简单服务器
from twisted.internet import reactor
from twisted.internet.protocol import Protocol,Factory
class SimpleLogger(Protocol):
def connectionMade(self):
print('Got connection from',self.transport.client)
def connectionLost(self,reason):
print(self.transport.client,'disconnected')
def dataReceived(self,data):
print(data)
factory = Factory()
factory.protocol = SimpleLogger
reactor.listenTCP(1234,factory)
reactor.run()
#代码清单14-9 使用协议LineReceiver改进后的日志服务器
from twisted.internet import reactor
from twisted.internet.protocol import Factory
from twisted.protocols.basic import LineReceiver
class SimpleLogger(LineReceiver):
def connectionMade(self):
print('Got connection from',self.transport.client)
def connectionLost(self,reason):
print(self.transport.client,'disconnected')
def lineReceived(self,line):
print(line)
factory = Factory()
factory.protocol = SimpleLogger
reactor.listenTCP(1234,factory)
reactor.run()
#代码清单15-1 简单的屏幕抓取程序
from urllib.request import urlopen
import re
p = re.compile('<a href ="(/jobs/\\d+)/">(.*?)</a>')
text = urlopen('http://python.org/jobs').read().decode()
for url,name in p.findall(text):
print('{} ({})'.format(name,url))
'''
<h1>Pet Shop
<h2>Complaints</h3>
<p>There is <b>no <i>way</b> at all</i> we can accept returned parrots.
<h1><i>Dead Pets</h1>
<p>Our pets may tend to rest at times,but rarely die within the warrantly period.
<i><h2>News</h2></i>
<p>We have just received <b>a really nice parrot.
<p>It's really nice.</b>
<h3><hr>The Norwegian Blue</h3>
<h4>Plumage and <hr>pining behavior</h4>
<a href="#norwegain-blue">More information<a>
<p>Features:
<body>
<li>Beautiful plumage
'''
#下面是Tidy修复后的版本:
<!DOCTYPE html>
<html>
<head>
<title></title>
</head>
<body>
<h1>Pet Shop</h1>
<h2>Complaints</h2>
<p>There is <b>no <i>way</i></b> <i>at all</i> we can accept returned parrots.</p>
<h1><i>Dead Pets</i></h1>
<p><i>Our pets may tend to rest at times,but rarely die within the warrantly period.</i></p>
<h2><i>News</i></h2>
<p>We have just received <b>a really nice parrot.</b></p>
<p><b>It's really nice.</b></p>
<hr>
<h3>The Norwegain Blue</h3>
<h4>Plumage and</h4>
<hr>
<h4>pining behavior</h4>
<a href="#norwegain-blue">More information</a>
<p>Features:</p>
<ul>
<li>Beautiful plumage</li>
</ul>
</body>
</html>
#例如,假设你有一个混乱的HTML文件(messy.html),且在执行路径中包含命令行版Tidy,下面的程序将对这个文件运行Tidy并将结果打印出来:
from subprocess import Popen,PIPE
text = open('messy.html').read()
tidy = Popen('tidy',stdin=PIPE,stdout=PIPE,stderr=PIPE)
tidy.stdin.write(text.encode())
tidy.stdin.close()
print(tidy.stdout.read().decode())
#代码清单15-2 使用模块HTMLParser的屏幕抓取程序
from urllib.request import urlopen
from html.parser import HTMLParser
def isjob(url):
try:
a,b,c,d=url.split('/')
except ValueError:
return False
return a==d==''and b=='jobs' and c.isdigit()
class Scraper(HTMLParser):
in_link = False
def handle_starttag(self,tag,attrs):
attrs = dict(attrs)
url = attrs.get('href','')
if tag == 'a' and isjob(url):
self.url=url
self.in_link=True
self.chunks=[]
def handle_data(self,data):
if self.in_link:
self.chunks.append(data)
def handle_endtag(self,tag):
if tag == 'a' and self.in_link:
print('{} ({})'.format(''.join(self.chunks),self.url))
self.in_link=False
text = urlopen('http://python.org/jobs').read().decode()
parser = Scraper()
parser.feed(text)
parser.close()
#代码清单15-3 使用Beautiful Soup的屏幕抓取程序
from urllib.request import urlopen
from bs4 import BeautifulSoup
text = urlopen('http://python.org/jobs').read()
soup = BeautifulSoup(text,'html.parser')
jobs = set()
for job in soup.body.section('h2'):
jobs.add('{} ({})'.format(job.a.string,job.a['href']))
print('\n'.join(sorted(jobs,key=str.lower)))
#代码清单15-4 简单的CGI脚本
#!/usr/bin/env python
print('Content-type:text/plain')
print()## 打印一个空行,以结束首部
print('Hello,world!')
#代码清单15-5 显示栈跟踪的CGI脚本(faulty.cgi)
#!/usr/bin/env python
import cgitb;cgitb.enable()
print('Content-type:text/html\n')
print(1/0)
print('Hello,world!')
#代码清单15-6 从FieldStorage中获取单个值的CGI脚本(simple2.cgi)
#!/usr/bin/env python
import cgi
from = cgi.FieldStorage()
name = form.getvalue('name','world')
print('Content-type:text/plain\n')
print('Hello,{}!'.format(name))
#代码清单15-7 包含HTML表单的问候脚本(simple3.cgi)
#!/usr/bin/env python
import cgi
form = cgi.FieldStorage()
name = form.getvalue('name','world')
print("""Content-type:text/html
<html>
<head>
<title>Greeting Page</title>
</head>
<body>
<h1>Hello,{}!</h1>
<form action = 'simple3.cgi'>
Change name <input type = 'text' name='name' />
<input type = 'submit' />
</form>
</body>
</html>
""".format(name))
'''
在这个脚本开头,与以前一样获取CGI参数name,并将默认值设置为'world'。如果在浏览器
中打开这个脚本时没有提交任何值,将使用默认值。
接下来,打印了一个简单的HTML页面,其中的标题包含参数name的值。另外,这个页面还
包含一个HTML表单,该表单的属性action被设置为脚本的名称(simple3.cgi)。这意味着提交表
单后,将再次运行这个脚本。这个表单只包含一个输入元素——名为name的文本框。因此,如果
你在文本框中输入新名字并提交表单,标题将发生变化,因为现在参数name包含值。
'''
#https://wiki.python.org/moin/WebFrameworks
#JSON,http://www.json.org
#代码清单16-1 简单的测试程序
from area import rect_area
height = 3
width = 4
correct_answer = 12
answer = rect_area(height,width)
if answer == correct_answer:
print('Test passed')
else:
print('Test failed')
#代码清单16-3 使用模块subprocess调用外部检查器
import unittest,my_math
from subprocess import Popen,PIPE
class ProductTestCase(unittest.TestCase):
#在这里插入以前的测试
def test_with_PyChecker(self):
cmd = 'pychecker','-Q',my_math.__file__.rstrip('c')
pychecker = Popen(cmd,stdout=PIPE,stderr=PIPE)
self.assertEqual(pychecker.stdout.read(),'')
def test_with_PyLint(self):
cmd = 'pylint','-rn','my_math'
pylint = Popen(cmd,stdout=PIPE,stderr=PIPE)
self.assertEqual(pylint.stdout.read(),'')
if __name__ =='__main__':unittest.main()
#代码清单17-1 一个简单的Java类(JythonTest.java)
public class JythonTest {
public void greeting(){
System.out.println("Hello,world!");
}
}
#$ javac JythonTest.java
#代码清单17-2 一个简单的C#类(IronPythonTest.cs)
using System;
namespace FePyTest{
public class IronPythonTest{
public void greeting(){
Console.WriteLine("Hello,world");
}
}
}
#对于Microsoft .NET,命令如下:
#csc.exe /t:library IronPythonTest.cs
#《C语言入门经典(第5版)》 《C程序设计语言(第2版)》
#NumPy(http://numpy.org)
#一个简单的检测回文的C语言函数(palindrome.c)
#include <string.h>
int is_palindrome(char *text){
int i, n=strlen(text);
for(i=0;I<=n/2;++i){
if(text[i] != text[n-i-1]) return 0;
}
return 1;
}
#代码清单17-4 检测回文的Python函数
def is_palindrome(text):
n = len(text)
for i in range(len(text) // 2):
if text[i] != text[n-i-1]:
return False
return True
#代码清单17-5 回文检测库的接口(palindrome.i)
%module palindrome
%{
#include <string.h>
%}
extern int is_palindrome(char *text);
#下面是一个在Solaris系统中使用编译器cc的示例(这里假设$PYTHON_HOME指向Python安装目录):
# cc -c palindrome.c
# cc -I$PYTHON_HOME -I$PYTHON_HOME/Include -c palindrome_wrap.c
# cc -G palidrome.o palindrome_wrap.o -o _palindrome.so
Python程序练习(1)
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.mfbz.cn/a/597988.html
如若内容造成侵权/违法违规/事实不符,请联系我们进行投诉反馈qq邮箱809451989@qq.com,一经查实,立即删除!相关文章

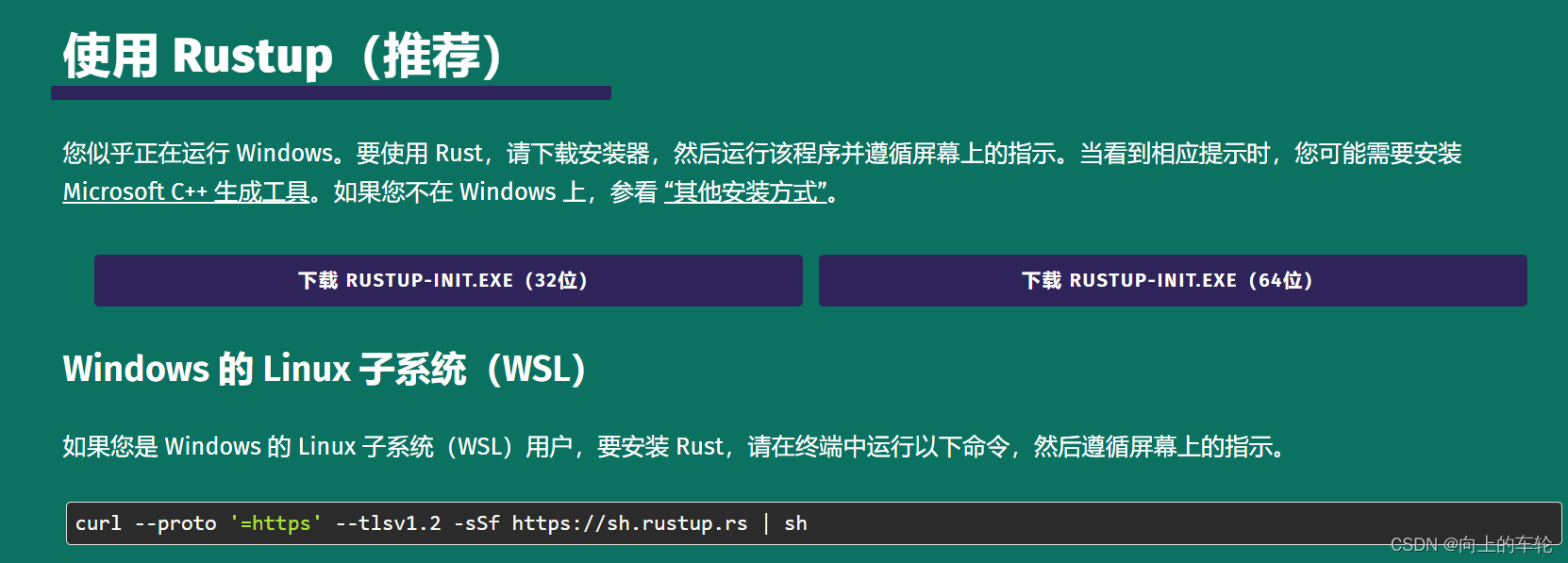
Rust开发工具有哪些?
目录
一、JetBrains公司的RustRover编辑
二、微软公司的Visual Studio Code
三、Rust编译工具 一、JetBrains公司的RustRover RustRover是由JetBrains开发的一款专为Rust开发量身定制的新兴IDE,目前还处于早期访问阶段。它支持Rust、Cargo、TOML、Web和数据库等…
学习笔记:【QC】Android Q telephony-data 模块
一、data init 流程图
主要分为3部分:
1.加载TelephonyProvider,解析apns-config.xml文件,调用loadApns将 xml中定义的数据,插入到TelephonyProvider底层的数据库中
2.初始化phone、DcTracker、TelephonyNetworkFactory、Conne…

【Pytorch】3.Transforms的运用
什么是Transforms 在PyTorch中,transforms是用于对数据进行预处理、增强和变换的操作集合。transforms通常用于数据载入和训练过程中,可以包括数据的归一化、裁剪、翻转、旋转、缩放等操作,以及将数据转换成PyTorch可以处理的Tensor格式。 Tr…

Redis-五大数据类型-Zset(有序集合)
五大数据类型-Zset(有序集合) 简介
Zset与Set非常相似,是一个没有重复元素的String集合。
不同之处是Zset的每个元素都关联了一个分数(score),这个分数被用来按照从低分到高分的方式排序集合中的元素。集…
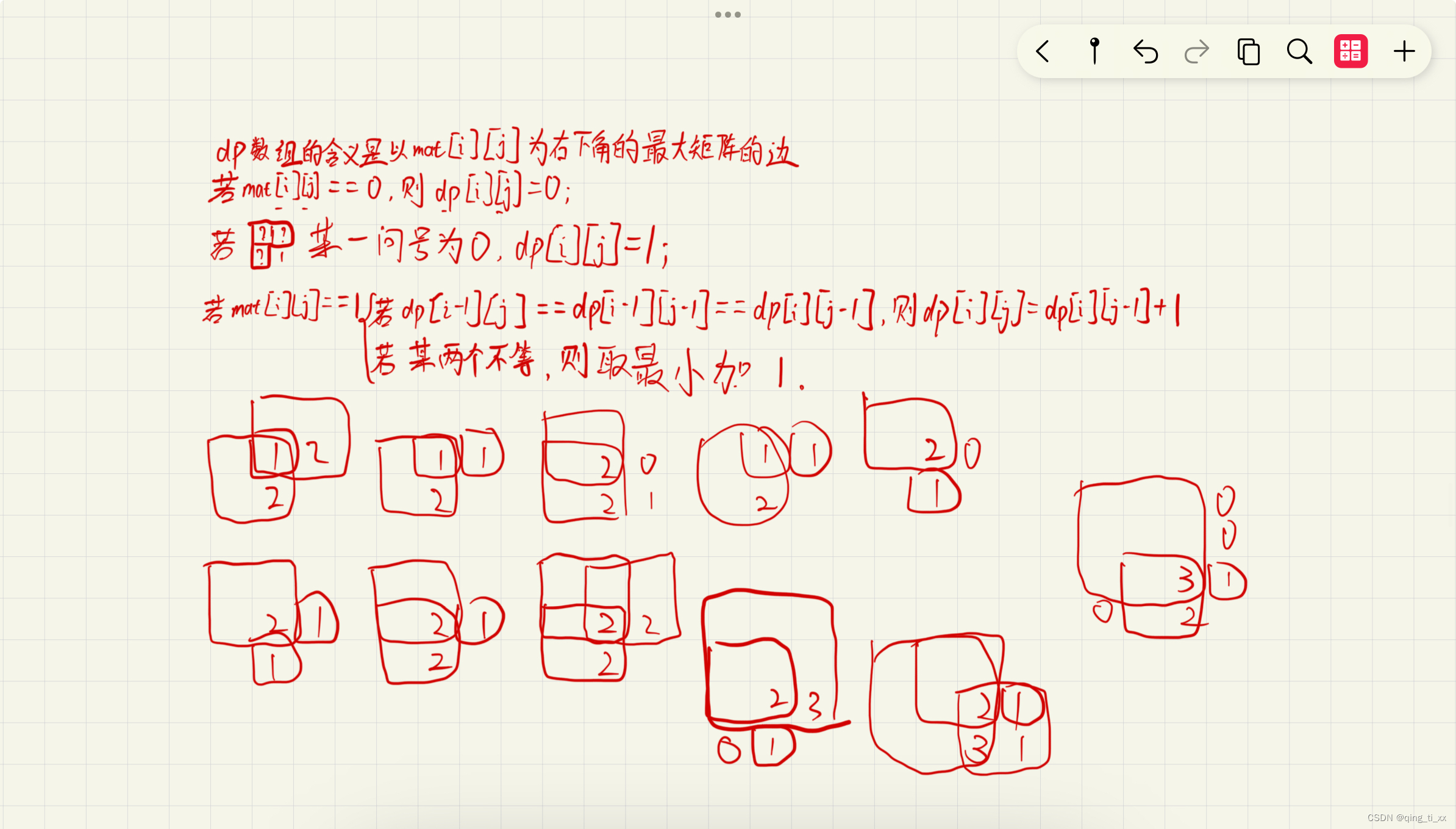
力扣:221. 最大正方形
221. 最大正方形
在一个由 0 和 1 组成的二维矩阵内,找到只包含 1 的最大正方形,并返回其面积。 示例 1: 输入:matrix [["1","0","1","0","0"],["1","0"…

#05 损失函数与优化器:深度学习的调谐师
文章目录 前言什么是损失函数?常见的损失函数 优化器的角色经典优化器 PyTorch中的损失函数与优化器实现一个损失函数选择一个优化器 神经网络训练中的应用结论 前言 深度学习的艺术和科学在于优化:它是一个寻找使模型性能最大化的过程。在这个过程中&am…
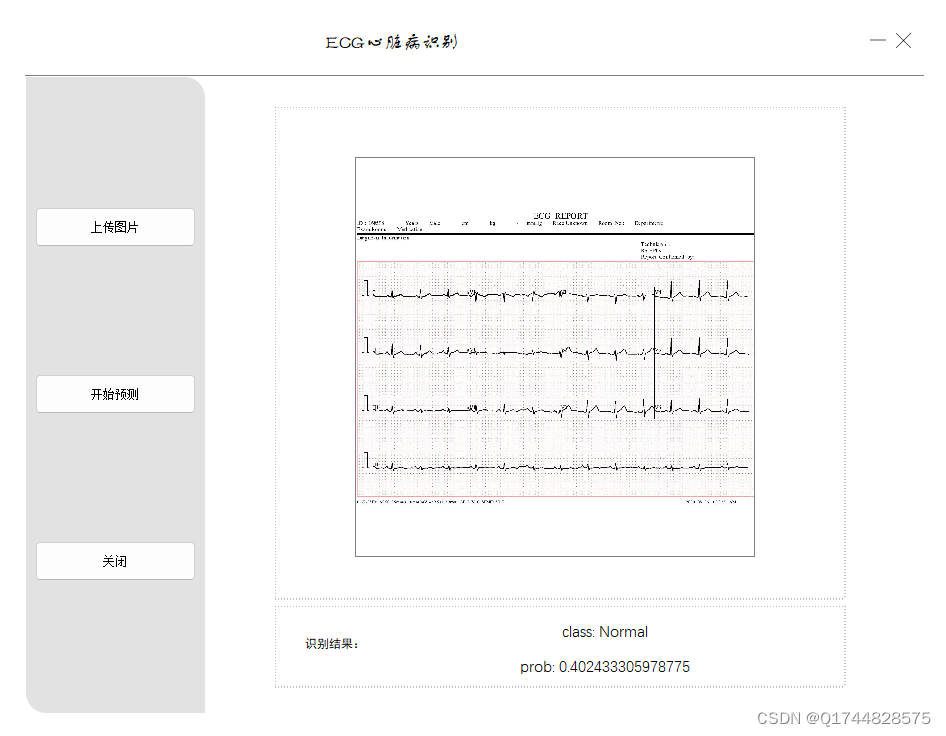
深度学习之基于Vgg16卷积神经网络心电图心脏病诊断系统
欢迎大家点赞、收藏、关注、评论啦 ,由于篇幅有限,只展示了部分核心代码。 文章目录 一项目简介 二、功能三、系统四. 总结 一项目简介 一、项目背景
心脏病是全球范围内导致死亡的主要原因之一,其早期的准确诊断对于患者的治疗和康复至关重…

【综自系统】配电室综合监控系统
安科瑞电气股份有限公司 祁洁 15000363176
一、系统简介
Acrel-2000E配电室综合监控系统,可实现开关柜运行监控、高压开关柜带电显示、母线及电缆测温监测、环境温湿度监测、有害气体监测、安防监控,可对灯光、风机、除湿机、空调控制等设备进行联动…
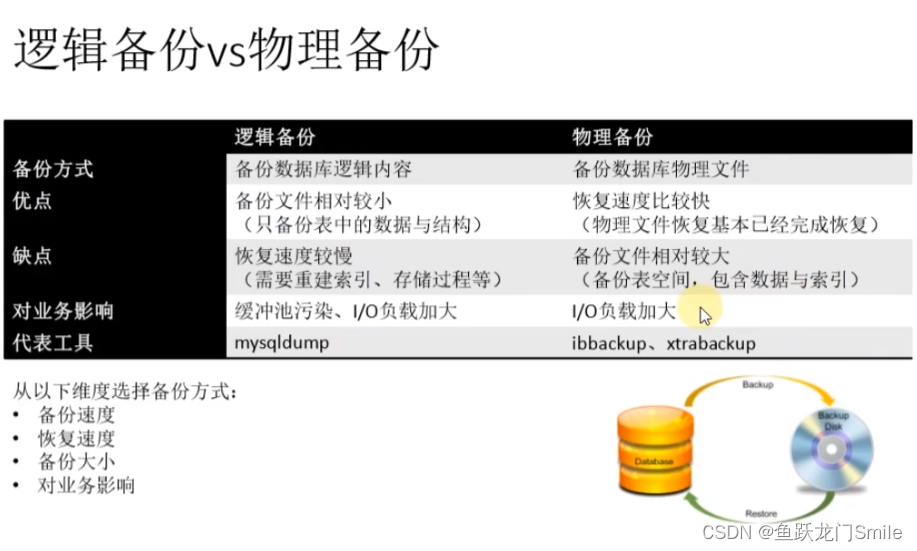
MySQL mysqldump备份恢复
目录
1. 备份类型
2. 逻辑备份VS物理备份
3. mysqldump工具
3.1 备份命令格式
3.2 备份选项
3.3 备份全库(结构和数据)
3.4 备份全库(仅结构)
3.5 备份全库(仅数据)
3.6 备份单个数据库(结构和数据)
3.7 备份单个数据库(仅结构)
3.8 备份单个数据库(仅数据)
3.9…
ACPWorkbench_for_BP10
一、菜单 文件菜单包含导入导出所有参数,导出flashbin文件和退出操作。文件菜单显示如下: Import Audio Settings:从音频配置文件中导入音频参数。 Export Audio Settings:将音频设置导出为音频配置文件。 Export Flash Binary Fi…
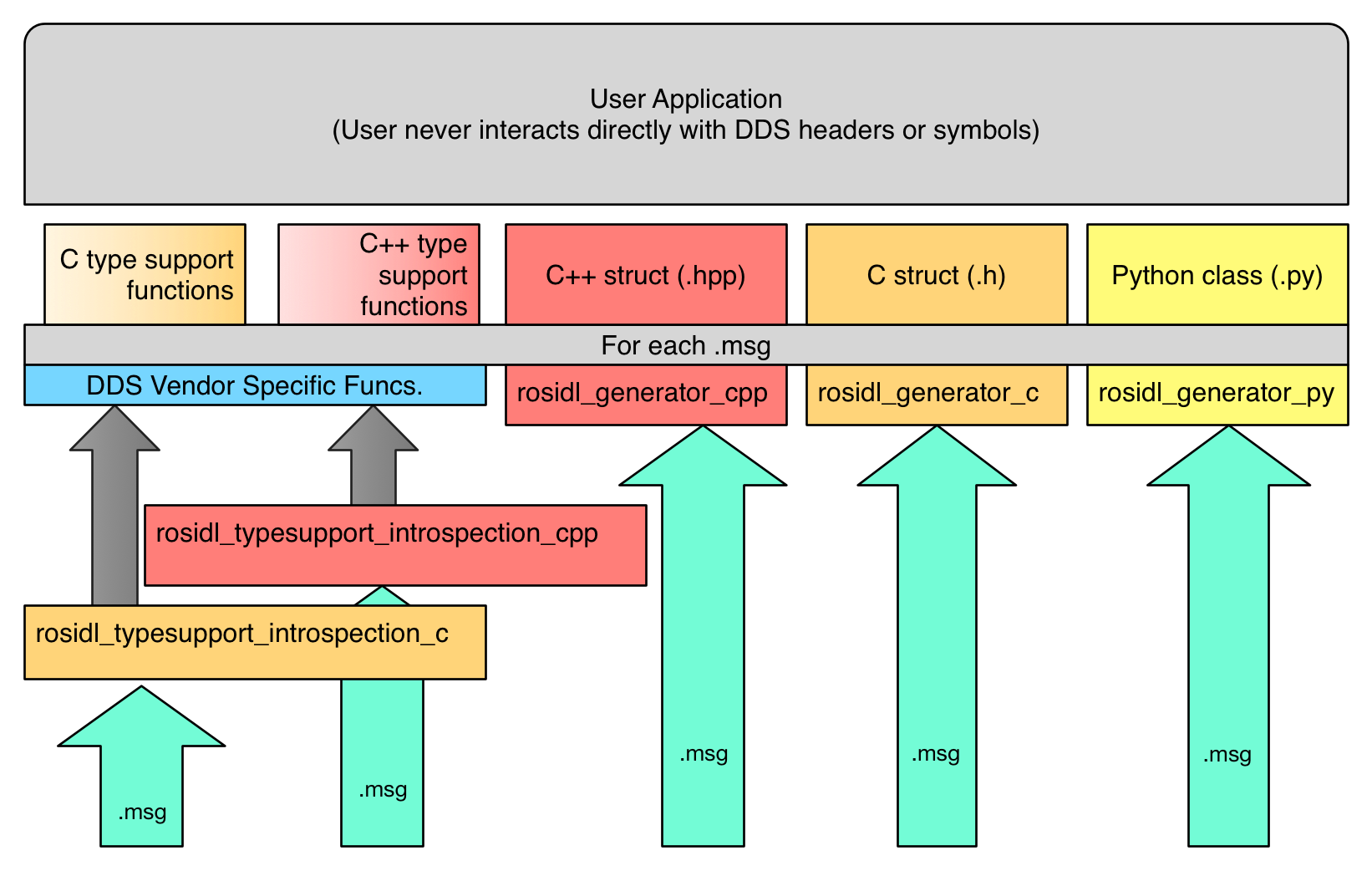
Type Specific Interfaces(Rolling特殊类型接口)
Type Specific Interfaces
一直以来,API的某些部分必然特定于所交换的消息类型,例如发布消息或订阅主题,因此需要为每个消息类型生成代码。下图布局了从用户定义的rosidl文件(如.msg文件)到用户和系统用于执行特定类型…

透明屏幕的可视角度有多大?在不同角度观看显示效果是否受影响?
透明屏幕的可视角度大小会因不同的技术、设计和应用场景而有所差异。以OLED透明屏为例,其可视角度通常可以达到178/178,这意味着在广阔范围内,观察者都能保持清晰的视觉效果。 然而,在不同角度观看透明屏幕时,显示效果…

【七十九】【算法分析与设计】并查集模板!!!并查集的实现_牛客题霸_牛客网,【模板】并查集 - 洛谷,并查集代码!!!
并查集的实现_牛客题霸_牛客网 描述 给定一个没有重复值的整形数组arr,初始时认为arr中每一个数各自都是一个单独的集合。请设计一种叫UnionFind的结构,并提供以下两个操作。 boolean isSameSet(int a, int b): 查询a和b这两个数是否属于一个集合 void u…
python从0开始学习(四)
目录 前言
1、算数运算符
1.1 //:整除运算符
1.2 %:取模操作
1.3 **:幂运算
2、赋值运算符
3、比较运算符
4、逻辑运算符
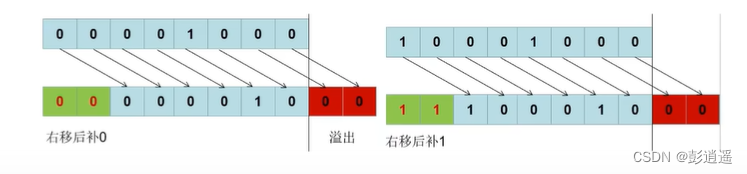
5、位运算符
5.1 &:按位与
5.2 |:按位或
5.3 ^:按位异或
5.4 ~:按位取反
5.5…
细粒度数据设计对于微调的重要性
原文地址:the-importance-of-granular-data-design-for-fine-tuning 利用数据设计来训练LLM,以充分利用上下文,同时解决“Lost-In-The-Middle”的挑战。 2024 年 5 月 2 日 介绍 对话设计师难道不是杰出的数据设计师吗? 请允许我详…
机器学习之基于Jupyter中国环境治理投资数据分析及可视化
欢迎大家点赞、收藏、关注、评论啦 ,由于篇幅有限,只展示了部分核心代码。 文章目录 一项目简介 二、功能三、系统四. 总结 一项目简介 机器学习之基于Jupyter中国环境治理投资数据分析及可视化项目是一个结合了机器学习和数据可视化技术的项目…
【算法练级js+java】重复给定字符n次
题目
Repeats the given string n times.(复制指定的字符串n次)
期望结果 /** * Repeats the given string n times. * * repeat(‘, 3) * // > **’ * * repeat(‘abc’, 2) * // > ‘abcabc’ * * repeat(‘abc’, 0) * // > “” **/ 代码…

一步教你网站怎么免费实现https,看这里!!
要想网站实现https访问最简单有效的方法就是安装SSL证书。只要证书安装上,浏览器就不会再有提示网站不安全或者访问被拦截的情况。现在我来教大家怎么去获取免费的SSL证书,又怎么安装来证书实现https访问。 一、选择免费SSL证书提供商
有多家机构提供免…
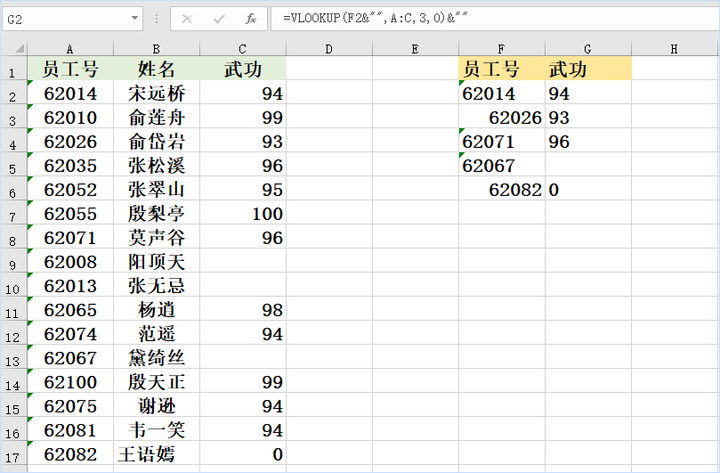
excel公式后面加的““是什么意思呢?
这个大体上有两种用意。
1.将数值转换成文本
VLOOKUP(F2,A:C,3,0)
举个使用VLOOKUP函数的场景,如下图所示,员工信息表A:C区域中,A列员工号是文本型数字,使用VLOOKUP函数查询找的时候,F列的员工号数值型、文本型都有…
最新文章
- 什么是蜜罐,在当前网络安全形势下,蜜罐能提供哪些帮助
- Flink 高可用之StandAlone-HA模式(一)
- 沉钒废水回收钒
- RTMP低延迟推流
- Jvppeteer生成PDF文件保存
- 【IoTDB 线上小课 03】时序数据库 VS 实时数据库,区别是?
- 全国大学生数学建模竞赛【集训营E题】丨 近5年赛题实现,模拟参赛体验
- OFDM802.11a的FPGA实现(十四)data域的设计优化,挤掉axi协议传输中的气泡
- 47.全排列
- 科技查新中的工法查新点如何确立与提炼?案例讲解!
- CUDA笔记
- MySQL和MongoDB区别
- 【全开源】keep健身小程序FastAdmin+ThinkPHP+UniApp
- GitLab使用记录
- 【DevOps】Dockerfile详解,做自己的docker镜像
- Java 中正则表达式简介与应用
- Linux技术---部署PXE服务器实现批量安装操作系统
- SQL编程----统计每个学校的答过题的用户的平均答题数
- 【字符串】Leetcode 12. 整数转罗马数字【中等】
- springboot报错‘url’ attribute is not specified and no embedded datasource could
- 尽微好物:从0到10亿+的抖音电商的TOP1“联盟团长”,如何使用NineData实现上云下云
- 什么是IP地址?
- 问题与解决:element plus对话框背景色覆盖失效
- python 合并 pdf
- CleanMyMac X有什么优势?到底好不好用?
- LeetCode解法汇总2760. 最长奇偶子数组
- 企业是否需要向个人信息主体提供《标准合同》副本文件?
- 软考中级难度排行榜,哪个科目更适合软考小白报考呢?
- # 从浅入深 学习 SpringCloud 微服务架构(七)Hystrix(3)
- # 从浅入深 学习 SpringCloud 微服务架构(三)注册中心 Eureka(2)